

AI will do exactly what the system allows it
A “don’t” in a prompt won’t help.

This is “Effective Delivery” — a newsletter from The Software House about improving software delivery through smarter IT team organization.
It was created by our senior technologists who’ve seen how strategic team management raises delivery performance by 20-40%.

TL;DR
Architecture is your real security layer,
Grant models only the access they need,
Treat every external input as a potential threat,
Permission checks belong in the code.
Contents
3. Guard every tool and operation
Hey! Aleksander here.
Most IT teams I talk to spend a lot of time on prompts.
Prompts do matter, and they shape how the model works.
But when those same IT teams start using prompts to enforce security rules, I get nervous.
Writing “do not do this” in a prompt gives you no real guarantee the model will comply.
A longer context window, a conflicting instruction, or a misread edge case can cause it to skip what seemed obvious.
Security cannot rest on what AI should not do.
It must rest on what the system will not let it do.
Less AI — fewer problems
Despite all the hype around AI, I hold a clear position.
The less unnecessary AI in an application, the better.
If a problem can be reasonably solved without it, that is the right call.
You spare yourself unclear edge cases and extra costs.
And you avoid the surprises that come with introducing a nondeterministic element into the system.
When AI does belong, it works best on unstructured data, such as documents, messages, text, and natural language.
Beyond choosing where to use AI, you also need to decide what it can touch.
The model should not have access to everything by default.
Before implementation, define which resources, files, data, and operations the model needs to do its job.
Give it only those.
Broad access “just in case” sounds harmless, but a wider access scope means a wider error surface.


Validate input and output
Any information entering the prompt, conversation, or model context from outside the system is potentially risky.
User messages are not the only risk.
Document content, a webpage fragment, a task description, and any other text the model receives for processing all counts.
Before that information reaches the main process, check whether the system should process it.
This matters most in chat systems, where the interaction volume is high and users have a lot of freedom in what they submit.

Prompt injection is a broad topic, and many tools exist to detect these risks.
The key principle is simple.
Do not treat external input as a trusted instruction for the system.
Apply the same scrutiny to what the model returns.
Before a response reaches the user or feeds further into the system, check for hallucinations and topic drift.
Check that the model has stayed within the expected tone, language, and application rules.
The stakes are highest when AI generates documents, summaries, or recommendations that decisions will depend on.
🇵🇱 Z Polski? Wpadnij na mój własny Substack i sprawdź jak rozkminiam inne strategiczne decyzje projektowe.
Guard every tool and operation
Agentic AI systems give the model a set of tools it can select and run depending on the operation.
Two things need attention.
First, which tools a user can see and run should depend on that user’s role, permissions, and tier in the application.
Not every user should have the same toolset available.
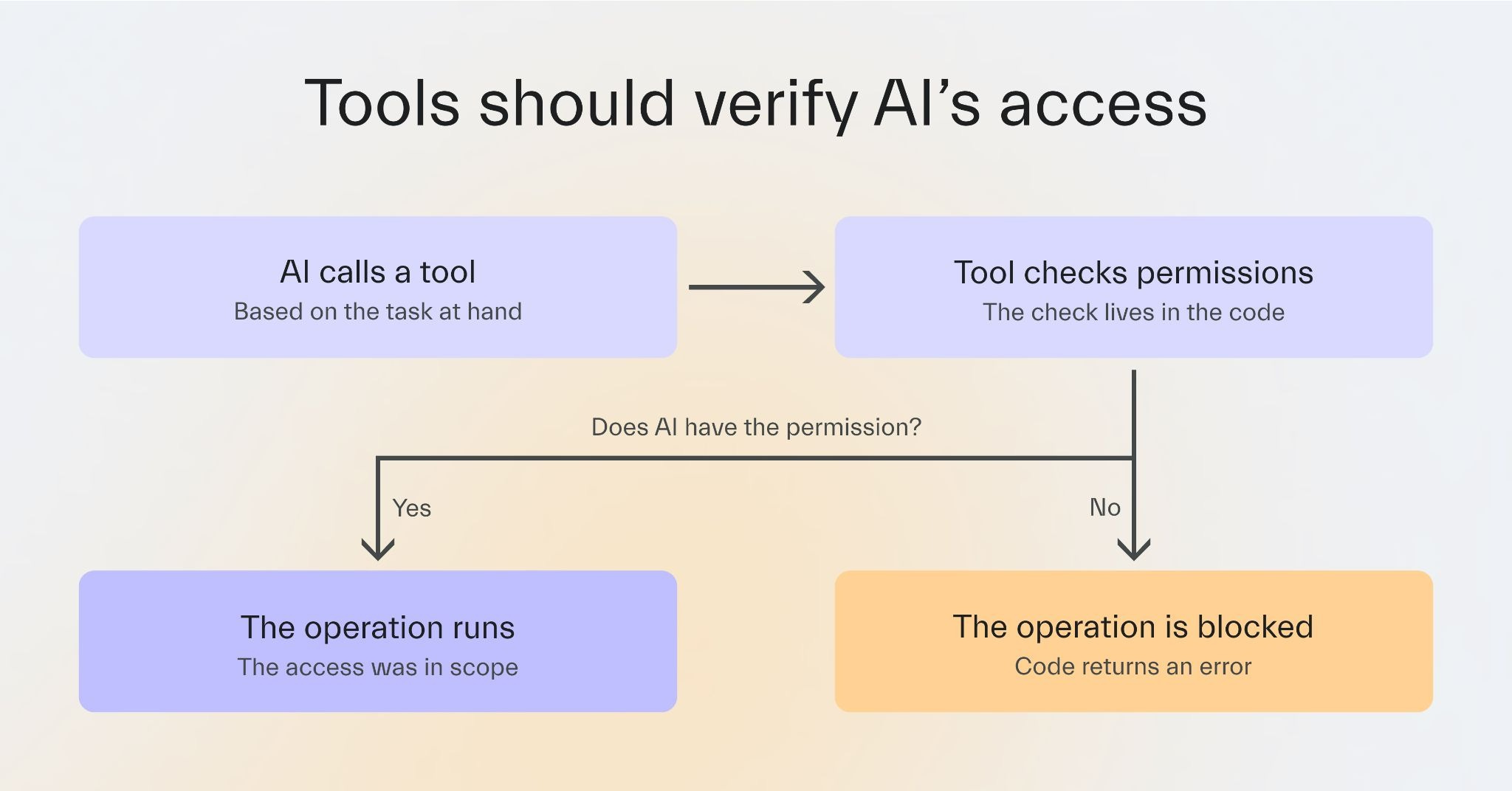
Second, each tool must run its own permission check before executing any operation.
That check belongs in the code.
Even if the model calls the tool, the code must be able to return an error saying this user cannot run this operation.
For critical operations, do not let the model decide on its own to execute them.
Treat AI as the component that prepares intermediate data and leaves final execution to the system.
The system then validates that data and maps it to the actual operation.
Working with a client on a summary tool, I hit this problem.
Instead of letting the model build a database query, I asked it to produce a JSON config describing what needed to happen.
The system then used that JSON to build the actual query.
That way the application’s own safeguards stayed in the loop and could reject unauthorized operations.
My position on direct database access for AI is straightforward.
Avoid it.
The model can generate a query it should not, or misinterpret what the user intended.
When direct database access is unavoidable, four rules apply.
Read-only access only, no writes or deletes,
In multi-tenant systems, restrict the data scope to the current client,
Run an additional review pass on any SQL the model generates,
Validate query results before they travel further through the system.
Cost monitoring belongs in this plan too.
Track not only implementation costs but the ongoing cost of every interaction.
Without per-user limits and real-time monitoring, one broken scenario can generate costs far beyond anything you planned.
An LLM Gateway between your application and the model handles rate limiting, cost tracking, and usage control from day one.
AI is not just another feature in the app.
Deploying it means thinking about security, access, limits, and control layers from day one.
It is closer to giving a user access to your internal tools than to adding another endpoint.
Build the system so AI cannot cause real harm when it misinterprets an instruction.
Design it to hold firm when the model tries to run an operation it should not run.
Prompts can help the model work correctly.
Architecture limits the consequences when it does not.
Next time
Andrzej Wysoczanski will look at the idle time that appears when engineers wait for AI-generated code to compile.
He will share concrete approaches for turning that window into productive work.
Back in 2 weeks 🤚
Would a friend of yours enjoy reading such stories?
Share Effective Delivery (effectivedelivery.io)

Olek recommends

Help us pay the bill for bitcoin mining

Published with a smirk by The Software House
Twarda 18, Warsaw, Poland
tsh.io →
 | A guest post by
|